
Machine Learning Universe: A Big Picture
Published:
There are many different algorithms in the machine learning universe. Each algorithm has its own intuition, use, advantages, and disadvantages. Click for more info.
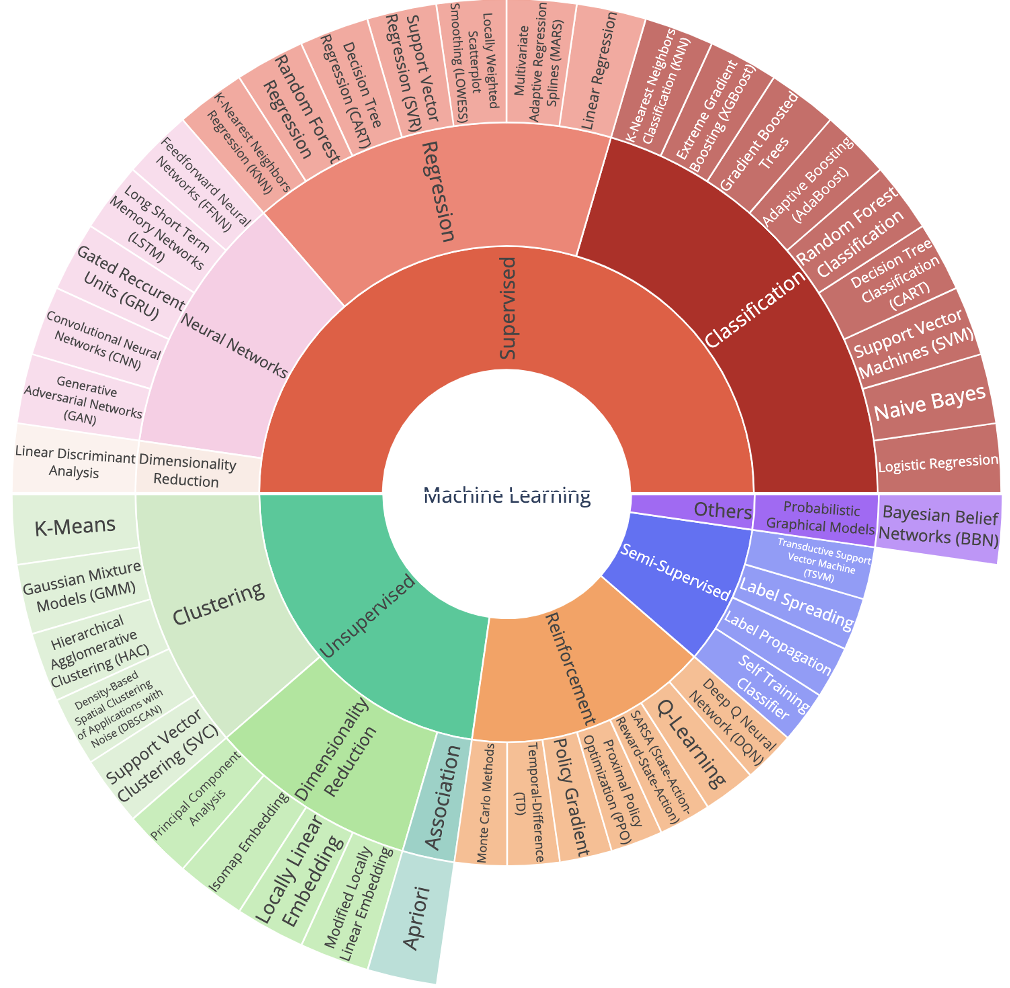
This figure shows the general algorithms available out there. Of course more and more algorithms are developed each day, but the general framework remains the same for quite some time.
We can think of the algorithms in the following categories:
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
- Reinforcement learning
Supervised learning
What does supervised learning means? It means that we have a task, say regression or classification, and we want to develop a black box to predict the true answer for new samples.
The term supervised means that we have something to train for. Say we want to learn multiplication. Having examples with answers helps. Hence, we use a supervised model suitable for the task, and give it the training samples, and train that model with those samples. Then we test the performance of the model.
Supervised learning algorithms mainly face the classic tasks of regression or classification. Now, if we look at the figure above, we can see another class as neural networks. Truth be told, neural networks is nothing but another method. It is not a class like regression or classification. However, due to its power and wide variety of applications, it is separated. For example, the feed-forward neural networks are standard forms of neural networks used in regression and classification taks. LSTM and GRU are designed specifically to deal with sequential data, that is, the typical tasks in Natural Language Processing (NLP) or in time-series analysis tasks. CNN are specially designed neural networks to deal with multi-dimensional data, specially images. So, as you can see, neural networks are very powerful in dealing with supervised learning problems, and the reason for it is that capacity of neural networks does not saturate with more data. In other words, in general, the more data we pour into the neural network models we can get better performances. This feature is not common is machine learning algorithms.
Unsupervised learning
The goal of unsupervised learning is different to that of a supervised learning. Say you have a set of data and you want to categorize it. Let’s assume that want to categorize it as clusters, however we don’t have the true label; that is, the cluster of each sample. So we want to take a look at the data and say: Hmmm, we have probably 10 clusters, and categorize each sample as one of those hypothetical clusters. This is an unsupervised learning task because we don’t have the true label. Famous algorithms like K-means do exactly these sort of tasks.
It is good to give another example as well for the unsupervised learning because it is something less intuitive than that of supervised learning. Another example of unsupervised learning is dimension reduction. We often face high dimensional data that is computationally costly to deal with them directly. A common technique there is is to look at the data and try to reduce its size while keeping the information as much as possible. This is a typical type of dimension reduction task. A famous method for this is Principle Component Analysis (PCA). This is again an unsupervised learning method.
These two examples gives us the two main members of the family of unsupervised learning group, that is:
- Clustering algorithms
- Dimension reduction